
개발자들은 고급 언어 모델을 애플리케이션에 통합할 효율적인 방법을 찾고 있습니다. INTELLECT-3은 오픈 소스 기반과 추론 작업에서 강력한 성능을 보여주며 매력적인 선택지로 부상하고 있습니다. Prime Intellect가 개발한 이 모델은 1,060억 개의 매개변수를 가진 MoE(Mixture-of-Experts) 아키텍처를 특징으로 하며, 복잡한 계산을 고효율로 처리할 수 있습니다.
INTELLECT-3 이해하기: 오픈 소스 강자
Prime Intellect는 INTELLECT-3 를 완전한 오픈 소스 모델로 공개하여 연구자와 개발자가 독점적 장벽 없이 기능을 맞춤 설정하고 확장할 수 있도록 지원합니다. 이러한 투명성은 강화 학습(RL) 및 에이전트 AI 시스템과 같은 분야에서 혁신을 촉진합니다. 모델 가중치, 훈련 프레임워크, 데이터셋, RL 환경 및 평가 도구를 포함한 전체 패키지는 Prime Intellect의 저장소에서 직접 액세스할 수 있습니다.

본질적으로 INTELLECT-3는 GLM-4.5-Air 기본 모델을 기반으로 하는 1,060억 개의 매개변수를 가진 MoE 아키텍처를 사용합니다. MoE 설계는 입력을 전문 "전문가" 하위 네트워크로 라우팅하여 컴퓨팅 사용을 최적화하고 추론을 가속화합니다. 예를 들어, 처리 중에 모델은 쿼리와 관련된 매개변수의 하위 집합만 활성화하여 정확도를 유지하면서 지연 시간을 줄입니다. 이러한 설정은 수학적 유도 또는 코드 생성과 같이 선택적 전문 지식이 필요한 작업에 특히 효과적입니다.
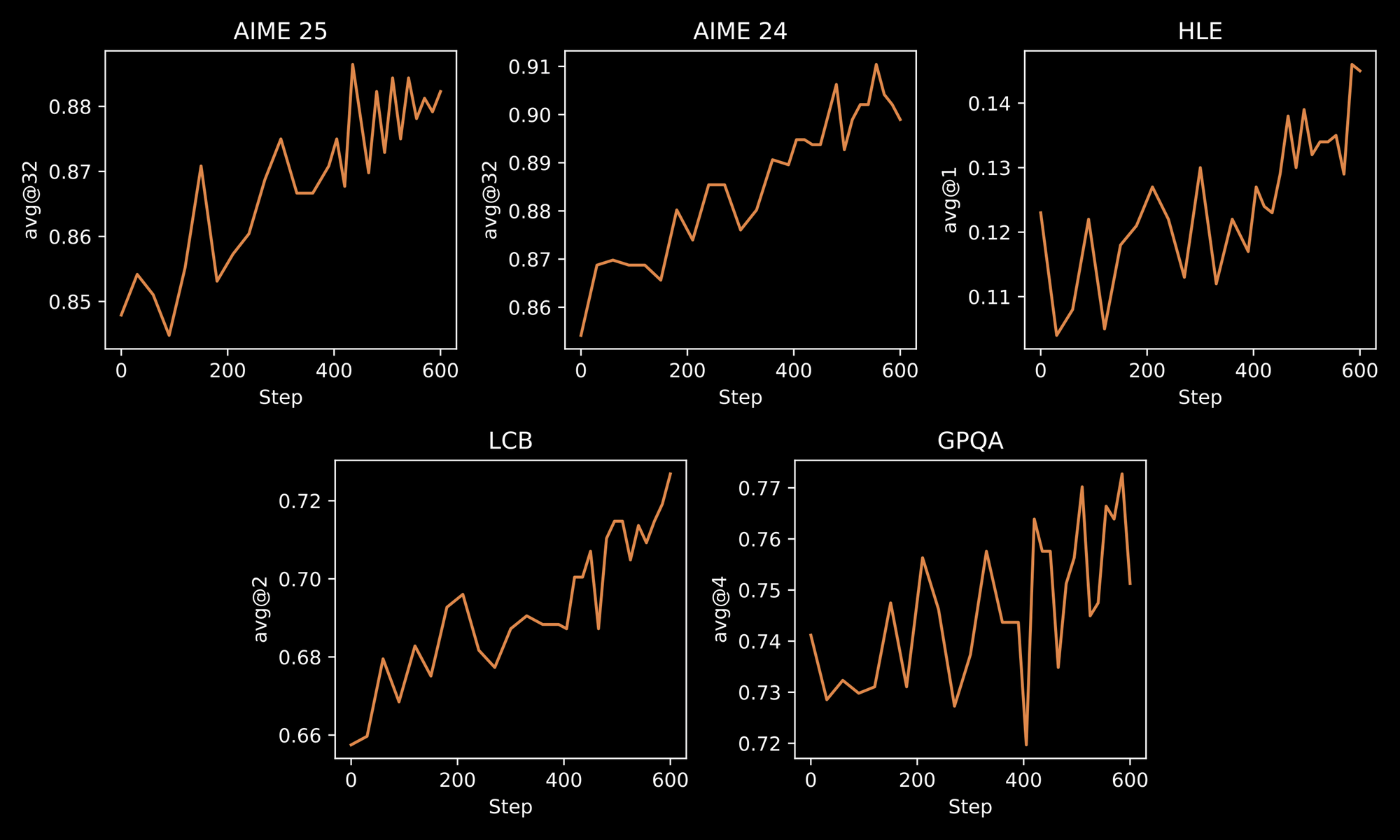
훈련 과정은 INTELLECT-3의 견고함을 강조합니다. 엔지니어는 큐레이션된 데이터셋에 대한 초기 지도 미세 조정(SFT)과 맞춤형 prime-rl 프레임워크를 사용한 대규모 RL을 따르는 2단계 방법론을 적용합니다. prime-rl은 비동기 오프-폴리시 RL 시스템으로 작동하여 방대한 병렬 시뮬레이션을 효율적으로 처리합니다. 반복적인 문제 해결 또는 다단계 계획과 같은 동적 환경에서 모델 동작이 개선되어 이러한 이점을 얻을 수 있습니다.
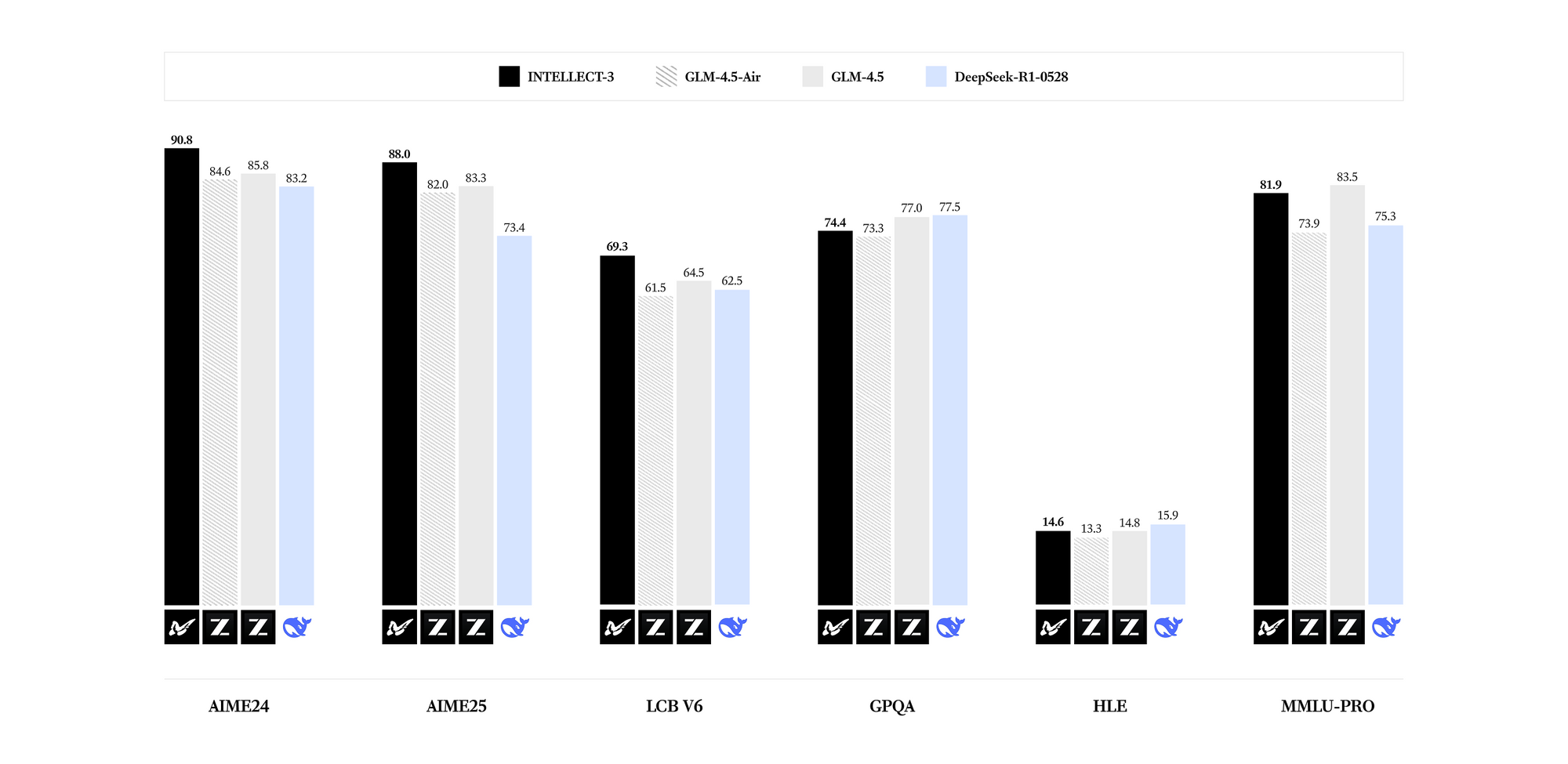
INTELLECT-3는 전문 분야에서 탁월한 성능을 발휘합니다. 벤치마크 결과, 수학(예: GSM8K 점수 95% 초과), 코딩(HumanEval 통과율 85% 이상), 과학(GPQA 정확도 60% 이상), 추론(MMLU 점수 80% 근접) 등 매개변수 수 대비 최첨단 결과를 보여줍니다. Llama 3.1 70B와 같은 더 밀집된 모델과 비교할 때, INTELLECT-3는 희소 활성화 패턴 덕분에 동등한 하드웨어에서 최대 2배 더 빠른 추론으로 우수한 효율성을 달성합니다. 결과적으로, 출력 품질을 희생하지 않고 리소스 제약이 있는 환경에 배포할 수 있습니다.
지원 인프라는 오픈 소스 매력을 더욱 높입니다. Verifiers & Environments Hub는 간단한 퍼즐부터 고급 정리 증명기에 이르기까지 500개 이상의 RL 환경을 제공합니다.
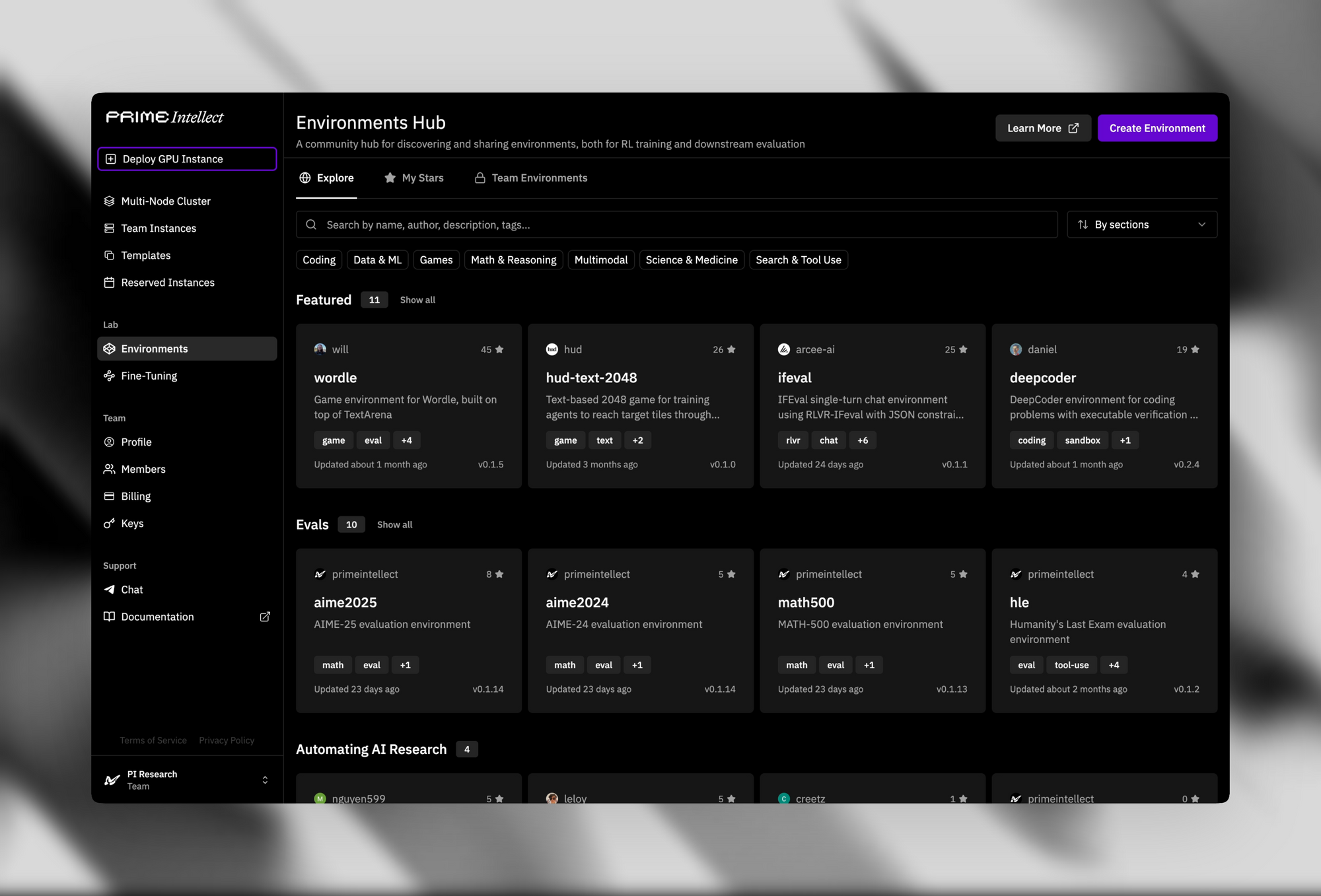
Prime 샌드박스 는 보안성이 높고 처리량이 뛰어난 코드 실행을 제공하여 훈련 또는 추론 중 에이전트 동작을 격리합니다. 개발자는 이러한 도구를 활용하여 소프트웨어 개발 파이프라인의 자율 에이전트와 같은 맞춤형 애플리케이션을 위해 INTELLECT-3를 미세 조정할 수 있습니다.
실제로 모델 가중치는 Hugging Face 또는 Prime Intellect의 GitHub를 통해 다운로드할 수 있습니다. 설치에는 PyTorch 및 Transformers 라이브러리와 같은 표준 종속성이 필요합니다. 모델을 로드하는 기본 스크립트는 다음과 같습니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
이 코드는 GPU 지원 하드웨어에서 모델을 초기화합니다. 그러나 프로덕션 규모의 사용을 위해서는 자체 호스팅에 상당한 컴퓨팅 자원(예: 여러 A100 GPU)이 필요하므로 호스팅된 API로 전환합니다. 따라서 오픈 소스 접근 방식은 기반을 마련하지만, API 통합은 배포를 효과적으로 확장합니다.
로컬 실험에서 벗어나 이제 관리형 서비스를 통해 INTELLECT-3에 액세스하는 방법을 살펴봅니다. 이러한 전환은 안정성을 보장하고 분산 추론의 복잡성을 처리합니다.
INTELLECT-3 API 액세스: 설정 및 인증
옵션 1 – Prime Intellect 네이티브 엔드포인트 (최대 성능 및 최저 지연 시간 권장)
API 액세스는 Prime Intellect 플랫폼에서 자격 증명을 얻는 것으로 시작합니다. app.primeintellect.ai에서 Prime Intellect 대시보드를 방문하고 필요한 경우 계정을 만드세요.
로그인한 후 API 키 섹션으로 이동하여 추론 권한이 활성화된 새 키를 생성하세요. 이 키는 모든 후속 요청을 인증하여 INTELLECT-3에 대한 보안 액세스를 보장합니다.
다음으로 환경을 구성합니다. 원활한 통합을 위해 API 키를 환경 변수로 설정하세요.
export PRIME_API_KEY="your-api-key-here"
팀 기반 워크플로의 경우 요청에 X-Prime-Team-ID 헤더를 포함합니다. 이 식별자는 사용량을 올바른 청구 풀로 라우팅하여 계정 간 요금 발생을 방지합니다. 팀 ID는 계정 설정 아래의 대시보드에서 검색할 수 있습니다.
이 API는 OpenAI 호환 인터페이스를 채택하여 openai-python과 같은 라이브러리를 이미 사용하는 경우 채택을 간소화합니다. 기본 URL을 https://api.pinference.ai/api/v1로 지정합니다. 이 엔드포인트는 INTELLECT-3 인스턴스를 호스팅하는 Parasail 및 Nebius를 포함한 최적화된 추론 공급자에게 요청을 프록시합니다. 결과적으로 기본 클러스터를 관리할 필요 없이 낮은 지연 시간으로 응답을 얻을 수 있습니다.
액세스를 확인하려면 모델 엔드포인트를 쿼리합니다. 여기에는 사용 가능한 모델이 나열되어 INTELLECT-3의 존재를 확인합니다(일반적으로 prime-intellect/intellect-3과 같은 핸들로). 빠른 확인을 위해 CLI 도구를 사용하세요.
prime inference models
또는 curl을 통해 GET 요청을 보냅니다.
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
응답은 id, max_tokens, context_window와 같은 매개변수를 자세히 설명하는 모델 객체의 JSON 배열을 반환합니다. INTELLECT-3는 128K 토큰 컨텍스트를 지원하여 장문의 추론 체인을 처리할 수 있습니다.
인증은 속도 제한 및 할당량으로 확장됩니다. Prime Intellect는 대시보드에서 볼 수 있는 계획에 따라 분당 및 일일 제한을 적용합니다. 청구 탭을 통해 사용량을 모니터링할 수 있으며, 이 탭에는 처리된 토큰 및 이루어진 API 호출이 기록됩니다. 제한으로 인해 워크플로가 제약을 받는 경우 플랫폼을 통해 원활하게 업그레이드할 수 있습니다.
또한 향상된 테스트를 위해 Apidog과 통합하세요. OpenAI 스키마를 Apidog으로 가져온 다음 INTELLECT-3 엔드포인트에 대한 요청을 시뮬레이션합니다. 이 방법은 잘못된 JSON 페이로드와 같은 문제를 조기에 식별합니다. Apidog의 무료 등급은 초기 설정에 충분하며 로컬 개발을 프로덕션 API로 연결합니다.
인증이 완료되면 요청을 작성하는 단계로 넘어갑니다. 다음 섹션에서는 INTELLECT-3에서 최적의 응답을 이끌어내기 위한 정확한 형식을 설명합니다.
옵션 2 – OpenRouter (즉시 액세스 및 통합 크레딧)
자체 호스팅 또는 Prime Intellect의 네이티브 추론 플랫폼 사용 외에도 INTELLECT-3는 OpenRouter에서도 공식적으로 사용할 수 있습니다. OpenRouter를 이미 사용하는 경우 별도의 Prime Intellect 계정 없이도 통합 결제, 자동 대체 라우팅 및 즉시 액세스를 제공하는 대안 게이트웨이를 제공합니다.
- 기본 URL: https://openrouter.ai/api/v1
- 모델 이름: prime-intellect/intellect-3
- 인증: OpenRouter API 키 (OPENROUTER_API_KEY)
- 자동 공급자 라우팅 (현재 Prime Intellect 클러스터에서 서비스 중)
- OpenRouter 크레딧으로 종량제 결제; 플랫폼 수수료로 인해 토큰당 비용이 약간 더 높음
두 엔드포인트 모두 동일한 요청/응답 스키마, 스트리밍, 도구 호출 및 JSON 모드를 지원합니다.
INTELLECT-3 API에 요청하기: 형식 및 예시
/chat/completions 엔드포인트를 통해 상호 작용을 시작하며, 이 엔드포인트는 대화형 및 작업 지향형 프롬프트를 처리합니다. model, messages, temperature, max_tokens 필드를 가진 JSON 객체로 요청을 구성합니다. messages 배열은 "system", "user", "assistant"와 같은 역할을 사용하여 채팅 기록을 모방합니다.
코드 생성의 기본 예시를 살펴보겠습니다. 다음과 같이 보냅니다.
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
이 코드는 INTELLECT-3의 코딩 능력을 활용하여 메모이제이션이 적용된 재귀 피보나치 구현을 출력합니다. temperature 매개변수는 창의성을 제어합니다. 낮은 값(예: 0.2)은 사실적 쿼리에 대한 확정적 출력을 선호하는 반면, 높은 값(최대 1.0)은 다양한 추론 경로를 장려합니다.
수학적 추론의 경우, 생각을 연결하도록 프롬프트를 구성합니다. INTELLECT-3의 RL 훈련은 단계별 검증을 시뮬레이션하므로 이 분야에서 빛을 발합니다. 예시:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
모델은 공리와 정리를 인용하여 엄격한 증명으로 응답합니다. response.choices[0].message.content를 통해 출력을 파싱하며, 이는 문자열로 도착합니다. 구조화된 데이터의 경우, 요청에 "response_format": {"type": "json_object"}를 추가하여 JSON 모드를 활성화하여 파싱 가능한 응답을 보장합니다.
고급 사용에는 INTELLECT-3가 외부 함수를 통합하는 도구 호출이 포함됩니다. 요청에 도구를 정의합니다.
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
모델이 도구를 호출하면 response.choices[0].message.tool_calls에 인수를 반환합니다. 외부에서 함수를 실행하고 후속 메시지로 결과를 다시 전달합니다. 이 패턴은 INTELLECT-3의 환경 훈련된 동작을 활용하여 에이전트 워크플로를 구축합니다.
오류 처리는 중요한 부분입니다. 일반적인 문제로는 401 (유효하지 않은 키), 429 (속도 제한), 400 (잘못된 요청)이 있습니다. 지수 백오프를 사용하여 재시도를 구현합니다.
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
응답에는 usage (prompt_tokens, completion_tokens, total_tokens)와 같은 메타데이터가 포함되며, 이를 최적화를 위해 기록합니다. INTELLECT-3는 깊이와 속도의 균형을 맞추면서 완료당 최대 4096개의 토큰을 처리합니다.
스트리밍 응답은 실시간 애플리케이션을 향상시킵니다. create 호출에 stream=True를 추가하면 클라이언트는 Server-Sent Events로 청크를 생성합니다. 이를 반복적으로 파싱합니다.
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
이 기술은 사용자가 증분 피드백을 기대하는 챗봇이나 라이브 코드 어시스턴트에 적합합니다.
요청 작성에 숙달했으니, 이제 성능을 평가합니다. 다음 섹션에서는 INTELLECT-3에 맞춤화된 벤치마킹 도구를 소개합니다.
INTELLECT-3 API 사용 최적화 및 평가
매개변수를 경험적으로 조정하여 API 호출을 최적화합니다. 처리량 향상을 위해 여러 메시지를 하나의 요청으로 일괄 처리하는 것으로 시작하여 평가 스위트에서 최대 10배의 효율성을 얻을 수 있습니다. Prime Intellect의 CLI는 이를 지원합니다.
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
이 명령은 100개의 GSM8K 샘플을 실행하여 정확도와 지연 시간 메트릭을 집계합니다. 결과를 분석하여 긴 생성에서 반복을 완화하는 top_p 또는 frequency_penalty를 조정합니다.
평가는 Verifiers Hub의 사용자 정의 환경으로 확장됩니다. RL 환경을 로드하고 정책으로 INTELLECT-3를 쿼리합니다.
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
보상은 개선 사항을 정량화하여 로컬에서 호스팅하는 경우 미세 조정을 안내합니다. API 전용 사용자의 경우 상호 작용을 벡터 데이터베이스에 기록하고 작업 성공률과 같은 하위 메트릭을 계산합니다.
보안 고려 사항도 중요합니다. 프롬프트 인젝션을 방지하기 위해 사용자 입력을 위생 처리하고, 시스템 프롬프트를 사용하여 경계를 강제합니다. INTELLECT-3의 RL 배경은 환각을 줄이지만, 중요한 애플리케이션의 경우 검증기를 통해 출력을 검증합니다.
스케일링에는 대시보드를 통한 모니터링이 포함됩니다. 토큰 임계값에 대한 알림을 설정하고, Prime Intellect가 클러스터용으로 노출하는 Prometheus와 같은 관찰성 도구와 통합합니다. 따라서 사용량이 증가해도 안정성을 유지할 수 있습니다.
이제 최적화를 처리했으니 비용을 고려해봅시다. 투명한 가격 정책은 지속 가능한 통합을 보장합니다.
INTELLECT-3 API 가격: 투명한 토큰 기반 모델
Prime Intellect는 토큰 소비를 중심으로 가격을 책정하며, 입력과 출력에 대해 별도로 요금을 부과합니다. 1,000토큰당 비용을 지불하며, 요율은 모델 및 공급업체에 따라 다릅니다. INTELLECT-3의 경우, 백만 입력 토큰당 약 $0.50, 백만 출력 토큰당 $1.50 정도의 경쟁력 있는 수치를 기대할 수 있지만, 정확한 값은 모델 엔드포인트 응답에 나타납니다.
| 공급자 | 입력 ($$ /백만 토큰) | 출력 ($$ /백만 토큰) | 비고 |
|---|---|---|---|
| Prime Intellect 직접 | ~$0.45–$0.60 | ~$1.30–$1.80 | 최저 비용, 대량 할인 |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | OpenRouter 플랫폼 수수료 포함 |
정확한 요율은 변동됩니다. 항상 대시보드 또는 모델 엔드포인트를 통해 최신 값을 확인하세요.
무엇을 선택해야 할까요?
- 최대 속도, 최저 비용, 또는 대용량 사용을 계획한다면 Prime Intellect 직접 옵션을 선택하세요.
- 50개 이상의 모델에 걸쳐 단일 API 키를 선호하거나, 즉시 온보딩이 필요하거나, 내장된 폴백 라우팅을 원한다면 OpenRouter를 선택하세요.
두 옵션 모두 동일한 INTELLECT-3 성능을 제공합니다. 워크플로에 맞는 것을 선택하세요. 많은 팀이 이중화를 위해 둘 다 동시에 사용하기도 합니다.
이 가이드의 나머지 부분(요청 형식, 스트리밍, 도구 호출, 최적화 등)은 Prime Intellect를 직접 호출하든 OpenRouter를 통해 호출하든 동일하게 적용됩니다.
아래의 전체 기술 구현 세부 정보를 계속 확인하고, 자신에게 가장 적합한 게이트웨이를 통해 오늘 INTELLECT-3로 구축을 시작하세요.
INTELLECT-3 API와의 고급 통합
오케스트레이션을 위해 INTELLECT-3를 LangChain 또는 LlamaIndex와 같은 에코시스템으로 확장할 수 있습니다. LangChain에서는 다음과 같습니다.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
이는 API를 검색 증강 생성(RAG) 파이프라인에 바인딩하여 외부 지식을 통해 정확도를 향상시킵니다.
마이크로서비스의 경우, INTELLECT-3로 프록시하는 FastAPI 래퍼를 통해 배포합니다.
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
이 엔드포인트를 Redis를 사용하여 속도 제한을 걸어 안전하게 노출하세요. 이러한 설정은 콘텐츠 생성기부터 연구 보조원에 이르는 SaaS 도구에 전력을 공급합니다.
엣지 케이스에도 주의가 필요합니다. 입력 길이를 동적으로 잘라내어 토큰 오버플로우를 처리하고, INTELLECT-3가 대기열에 있을 경우 더 작은 모델로 폴백합니다. Prime Intellect 사이트의 커뮤니티 포럼에서 문제 해결 스레드를 제공합니다.
결론: INTELLECT-3 API를 자신 있게 배포하세요
이제 INTELLECT-3 API 사용을 위한 포괄적인 툴킷을 갖게 되었습니다. 오픈 소스 기반부터 정밀한 요청 처리 및 비용 관리에 이르기까지, 이 가이드는 실제 배포에 필요한 모든 것을 제공합니다. Apidog을 사용하여 워크플로를 다듬고, 업데이트를 위해 변화하는 문서를 주시하세요.
이러한 기술을 점진적으로 구현하세요. 간단한 채팅으로 시작하여 에이전트로 확장해나가세요. INTELLECT-3의 효율성과 개방성은 기술 AI 프로젝트를 위한 최적의 솔루션으로 자리매김합니다. 오늘 바로 코딩을 시작하여 애플리케이션에 미칠 영향을 경험해보세요.