
大規模言語モデル(LLM)パイプラインの評価と最適化に苦労していませんか?LangWatchが登場しました。これは、カスタムLLMワークフローの監視、評価、微調整を簡単にする画期的なプラットフォームです。このガイドでは、LangWatchとは何か、なぜ素晴らしいのか、そしてAIプロジェクトを強化するためにそれをインストールして使用する方法について詳しく説明します。シンプルなチャットボットのセットアップ、LangWatchの統合、サンプル質問でのテストを、すべて分かりやすく進めていきます。さあ、始めましょう!
最大限の生産性で開発チームが協力できる統合されたオールインワンプラットフォームが欲しいですか?
Apidogはあなたのすべての要求に応え、Postmanをはるかに手頃な価格で置き換えます!
LangWatchとは何か、なぜ注目すべきなのか?
LangWatchは、LLM評価の厄介な問題に取り組むための頼りになるプラットフォームです。分類におけるF1スコア、翻訳におけるBLEU、要約におけるROUGEといった標準的な指標を持つ従来のモデルとは異なり、生成型LLMは非決定論的であり、特定が困難です。さらに、各企業は独自のデータ、微調整されたモデル、カスタムパイプラインを持っているため、評価は頭の痛い問題です。そこでLangWatchが輝きを放ちます!
LangWatchでできること:
- 実験と最適化:LLMパイプラインを簡単にテストし、改善します。
- パフォーマンスの監視:AIの動作をリアルタイムで追跡します。
- 結果の評価:データセットと評価ツールを使用して精度と品質を測定します。
- カスタムパイプラインのサポート:独自のデータとモデルで動作します。
チャットボット、翻訳ツール、カスタムAIアプリのいずれを構築している場合でも、LangWatchはLLMが最高の結果を出すことを保証するのに役立ちます。実際に見てみませんか?LangWatchをインストールして使ってみましょう!
LangWatchのインストールと使用に関するステップバイステップガイド
前提条件
始める前に、以下のものが必要です:
- Python 3.8以降:プロジェクトの実行用(python.org)。
- LangWatchアカウント:app.langwatch.aiでサインアップしてください。
- OpenAI APIキー:チャットボットのデモ用(platform.openai.comで取得)。
- コードエディター:VS Code、PyCharm、またはお好みのIDE。
- GitとDocker:オプション。ローカルでのLangWatchセットアップ用。
ステップ1:LangWatchにサインアップする
アカウントを作成する:
- app.langwatch.aiにアクセスし、無料アカウントにサインアップしてください。
- 「AI Bites」というデフォルトのプロジェクトが作成されます。このチュートリアルではこれを使用しますが、必要に応じて新しいプロジェクトを作成することもできます。
APIキーを取得する:
- LangWatchダッシュボードで、プロジェクト設定に移動し、
LANGWATCH_API_KEYを見つけてください。これは後で必要になります。

ステップ2:LangWatchでPythonプロジェクトをセットアップする
Pythonプロジェクトを作成し、LangWatchを統合してシンプルなチャットボットを追跡してみましょう。
- プロジェクトフォルダーを作成する:
- 新しいディレクトリ(例:
langwatch-demo)を作成し、その中に移動します:
mkdir langwatch-demo
cd langwatch-demo
2. 仮想環境をセットアップする:
- 依存関係を分離するために仮想環境を作成し、アクティブ化します:
python -m venv venv
source venv/bin/activate # Windowsの場合: venv\Scripts\activate
3. LangWatchと依存関係をインストールする:
- LangWatchとChainlit(チャットボットUI用)をインストールします:
pip install langwatch chainlit openai
4. チャットボットのコードを作成する:
app.pyというファイルを作成し、このコードを貼り付けてOpenAIのGPT-4o-miniモデルを使用したシンプルなチャットボットを構築します:
import os
import chainlit as cl
import asyncio
from openai import AsyncClient
openai_client = AsyncClient() # Assumes OPENAI_API_KEY is set in environment
model_name = "gpt-4o-mini"
settings = {
"temperature": 0.3,
"max_tokens": 500,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
}
@cl.on_chat_start
async def start():
cl.user_session.set(
"message_history",
[
{
"role": "system",
"content": "You are a helpful assistant that only reply in short tweet-like responses, using lots of emojis."
}
]
)
async def answer_as(name: str):
message_history = cl.user_session.get("message_history")
msg = cl.Message(author=name, content="")
stream = await openai_client.chat.completions.create(
model=model_name,
messages=message_history + [{"role": "user", "content": f"speak as {name}"}],
stream=True,
**settings,
)
async for part in stream:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
message_history.append({"role": "assistant", "content": msg.content})
await msg.send()
@cl.on_message
async def main(message: cl.Message):
message_history = cl.user_session.get("message_history")
message_history.append({"role": "user", "content": message.content})
await asyncio.gather(answer_as("AI Bites"))
5. OpenAI APIキーを設定する:
- OpenAI APIキーを環境変数として追加します:
export OPENAI_API_KEY="your-openai-api-key" # Windowsの場合: set OPENAI_API_KEY=your-openai-api-key
6. チャットボットを実行する:
- Chainlitアプリを起動します:
chainlit run app.py
- http://localhost:8000を開いてチャットボットUIを確認します。動作するか試してみてください!
ステップ3:追跡のためにLangWatchを統合する
次に、チャットボットのメッセージを追跡するためにLangWatchを追加しましょう。
- LangWatch用に
app.pyを修正する:
app.pyを更新してLangWatchを含め、main関数に@langwatch.trace()デコレーターを追加します:
import os
import chainlit as cl
import asyncio
import langwatch
from openai import AsyncClient
openai_client = AsyncClient()
model_name = "gpt-4o-mini"
settings = {
"temperature": 0.3,
"max_tokens": 500,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
}
@cl.on_chat_start
async def start():
cl.user_session.set(
"message_history",
[
{
"role": "system",
"content": "You are a helpful assistant that only reply in short tweet-like responses, using lots of emojis."
}
]
)
async def answer_as(name: str):
message_history = cl.user_session.get("message_history")
msg = cl.Message(author=name, content="")
stream = await openai_client.chat.completions.create(
model=model_name,
messages=message_history + [{"role": "user", "content": f"speak as {name}"}],
stream=True,
**settings,
)
async for part in stream:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
message_history.append({"role": "assistant", "content": msg.content})
await msg.send()
@cl.on_message
@langwatch.trace()
async def main(message: cl.Message):
message_history = cl.user_session.get("message_history")
message_history.append({"role": "user", "content": message.content})
await asyncio.gather(answer_as("AI Bites"))
2. 統合をテストする:
- Chainlitアプリを再起動します:
chainlit run app.py
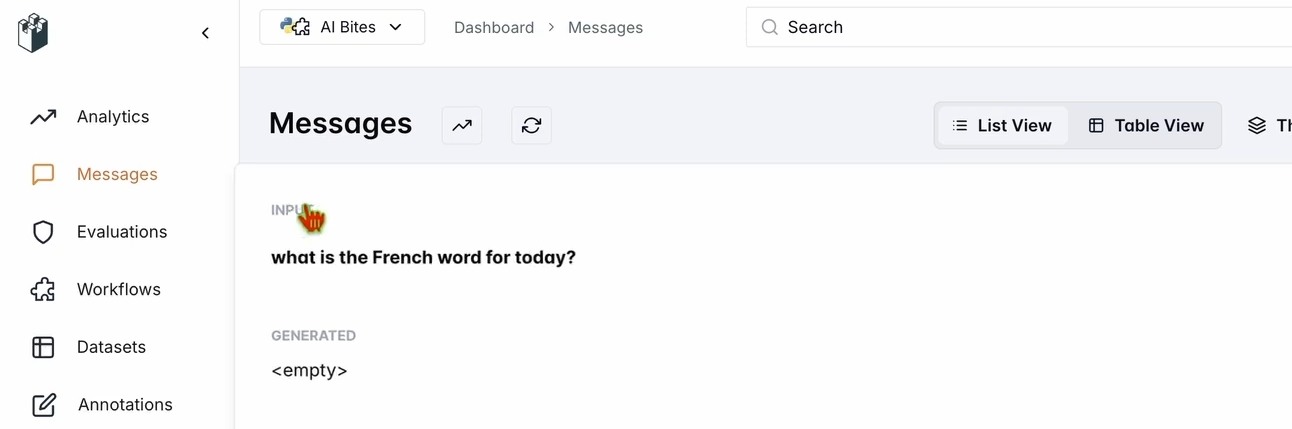
- チャットボットUIで、「今日のフランス語は何ですか?」と尋ねます。
- LangWatchダッシュボードを確認します:
- app.langwatch.aiにアクセスします。
- 左側のサイドバーからメッセージを選択します。
- あなたの質問とチャットボットの応答(例:「Aujourd’hui! 🇫🇷😊」)が追跡されていることを確認します。
ステップ4:チャットボットを評価するためのワークフローをセットアップする
チャットボットのパフォーマンスを評価するために、LangWatchでデータセットと評価ツールを作成しましょう。
- データセットを作成する:
- LangWatchダッシュボードで、データセットに移動し、新しいデータセットをクリックします。
- 少なくとも1つの質問と回答を含むシンプルなデータセットを追加します。例:
| 質問 | 期待される回答 |
|---|---|
| 今日のフランス語は何ですか? | Aujourd’hui |
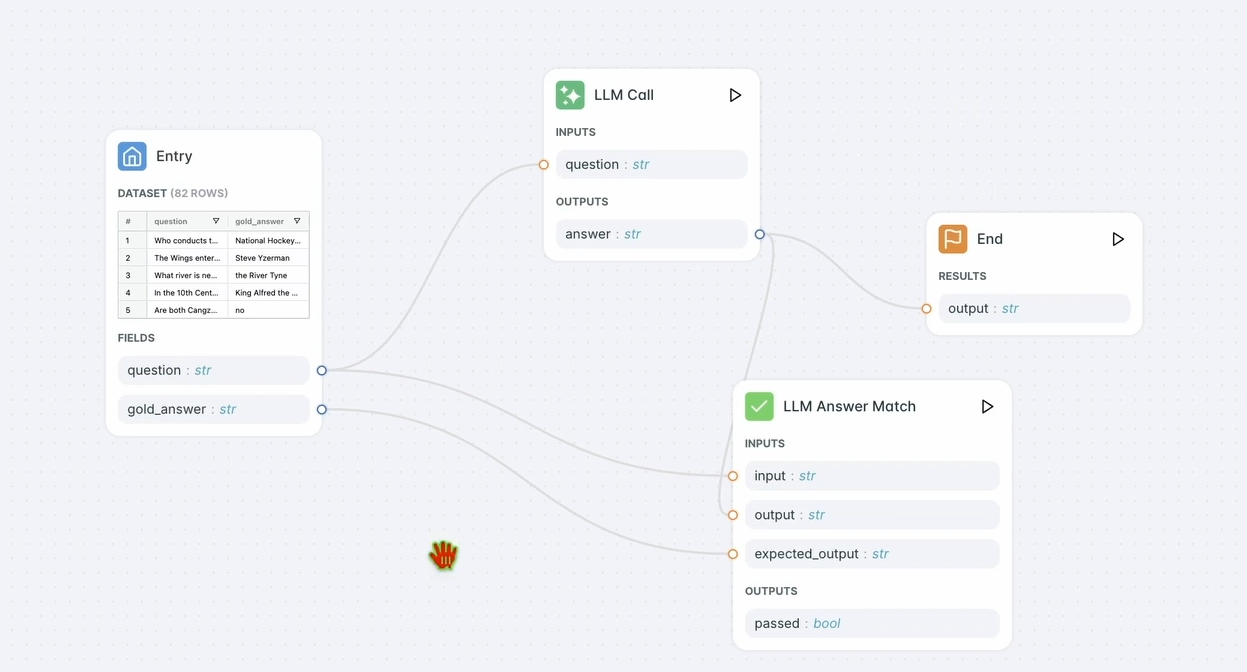
2. 評価ツールをセットアップする:
- LangWatchダッシュボードで、評価ツールに移動します。
- LLM回答一致評価ツールをワークスペースにドラッグします。
- 設定します:
- 入力質問をデータベースの入力質問(例:「今日のフランス語は何ですか?」)に設定します。
- 期待される出力もデータベースの応答(例:「Aujourd’hui」)に設定します。
- オプションで、評価ツールのLLMモデル(例:Llama、Gemini、またはClaude Sonnet)を変更して多様性を出します。
3. 評価ツールを実行する:
- ここまでワークフローを実行をクリックして評価ツールをテストします。
- チャットボットの応答が期待される出力と一致していることを確認するために結果をチェックします。
次のような表示になるはずです:
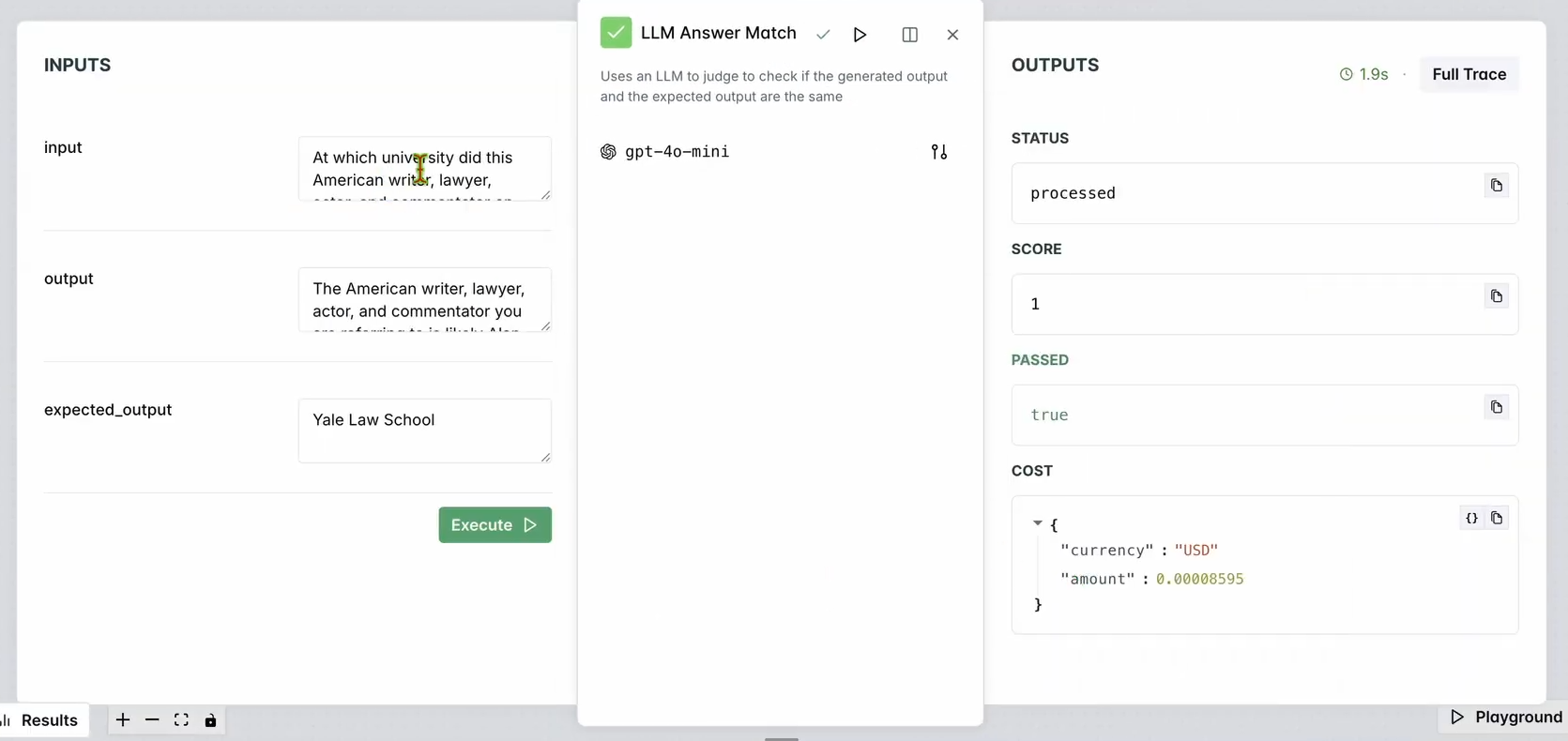
4. ワークフローを評価する:
- 上部のナビゲーションバーで、ワークフローを評価をクリックし、テストエントリを選択します。
- これにより、データセットに対してワークフロー全体が評価されます。結果は短い処理時間の後に表示されます。
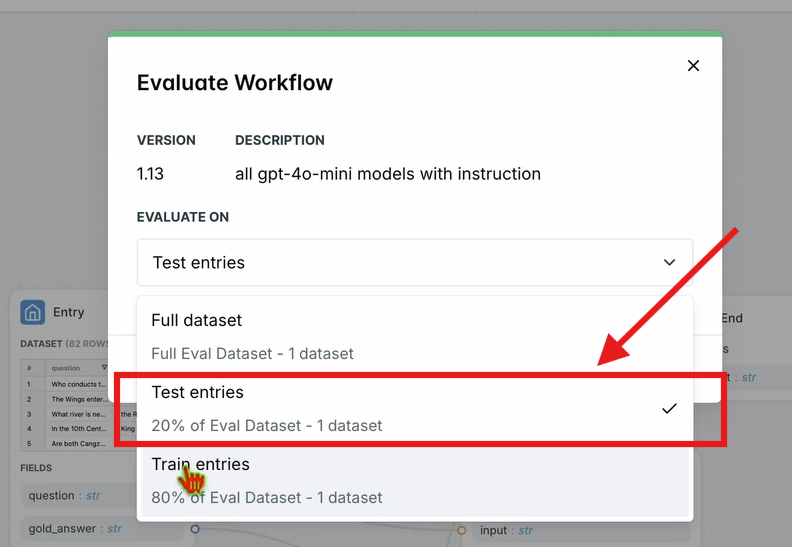
ステップ5:ワークフローを最適化する
評価が完了したら、チャットボットのパフォーマンスを最適化しましょう。
1. 最適化を実行する:
- LangWatchダッシュボードの上部ナビゲーションバーで、最適化をクリックします。
- チャットボットのプロンプトを微調整するためにプロンプトのみを選択します。
- 最適化が完了するまで数分待ちます。
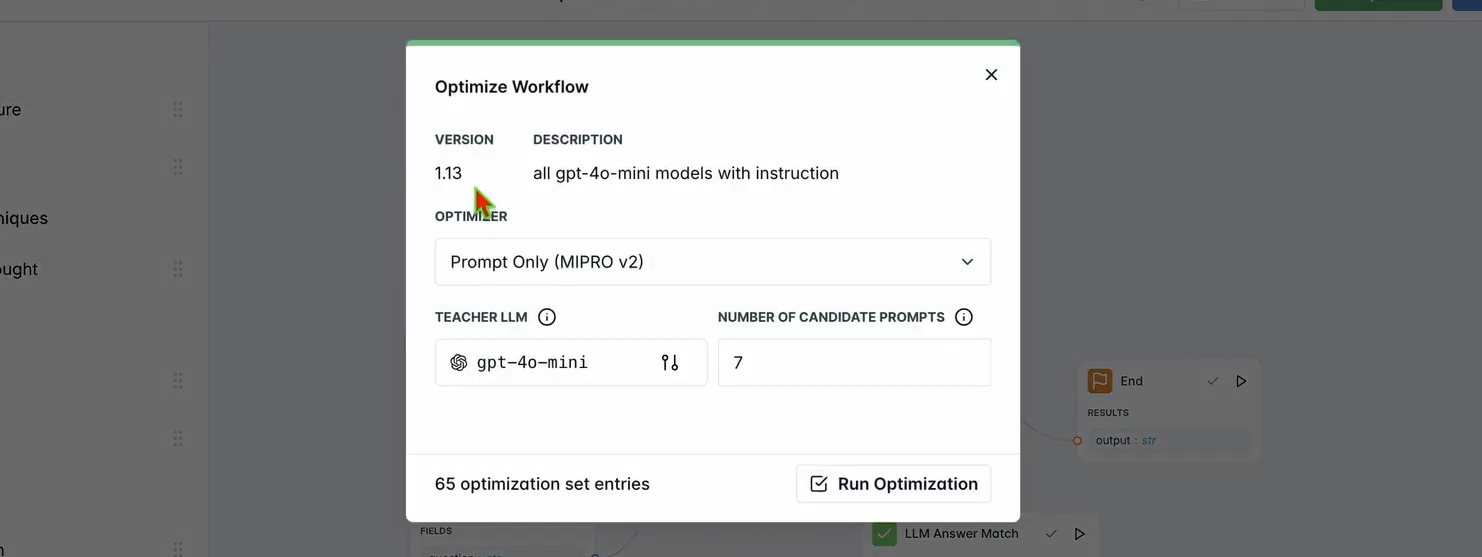
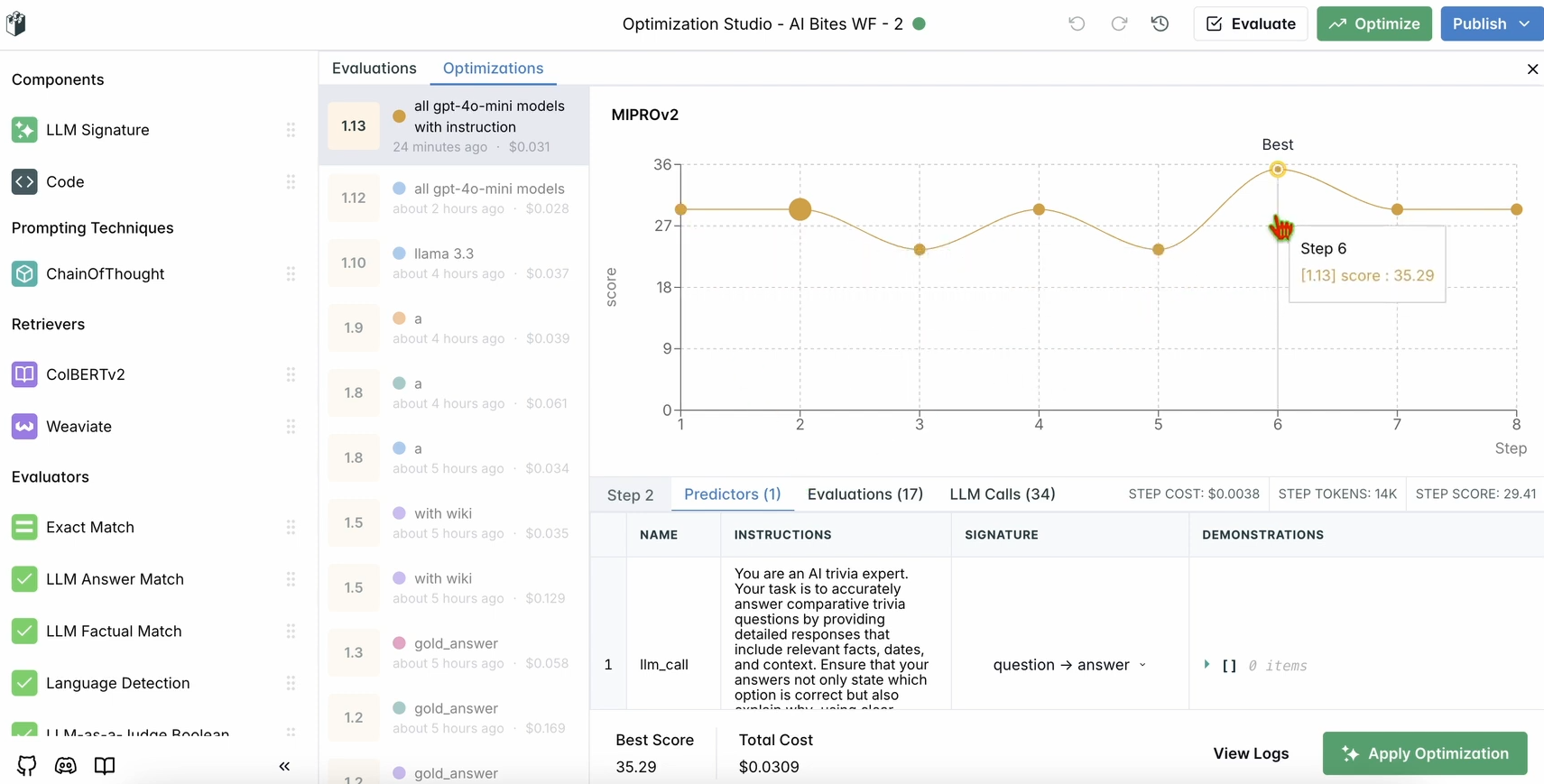
2. 改善点を確認する:
- ダッシュボードで最適化された結果を確認します。LangWatchの提案に基づいて、応答の精度または品質が向上しているはずです。
ステップ6:オプションのローカルLangWatchセットアップ
機密データでのテストのためにLangWatchをローカルで実行したいですか?以下の手順に従ってください:
- リポジトリをクローンする:
git clone https://github.com/langwatch/langwatch.git
cd langwatch
2. 環境をセットアップする:
- 環境設定ファイルの例をコピーします:
cp langwatch/.env.example langwatch/.env
3. Dockerで実行する:
- LangWatchサーバーを起動します:
docker compose up -d --wait --build
4. ダッシュボードにアクセスする:
- http://localhost:5560を開いてLangWatchのオンボーディングフローに入ります。
- プロンプトに従ってローカルインスタンスをセットアップします。
注:Dockerセットアップはテスト専用であり、本番環境向けにはスケーラブルではありません。本番環境では、LangWatch CloudまたはEnterprise On-Premisesを使用してください。
LangWatchを使う理由
LangWatchは、AIパイプラインを監視、評価、最適化するための統合プラットフォームを提供することで、LLM評価のパズルを解決します。プロンプトを調整したり、パフォーマンスを分析したり、チャットボットが正確な回答(フランス語で「today」に対する「Aujourd’hui」のように)を提供していることを確認したりする場合でも、LangWatchはそれを簡単に行えます。PythonやChainlit、OpenAIなどのツールとの統合により、LLMアプリの追跡と改善を数分で開始できます。
例えば、私たちのデモチャットボットは絵文字を使ってツイートのような短い応答をするようになり、LangWatchはそれが正確で最適化されていることを保証するのに役立ちます。スケールアップしたいですか?データセットに質問を追加したり、評価ツールで異なるLLMモデルを試したりしてください。
結論
これで終わりです!LangWatchとは何か、そのインストール方法、そしてチャットボットの監視と最適化にどのように使用するかを学びました。Pythonプロジェクトのセットアップから、メッセージの追跡、データセットによるパフォーマンス評価まで、LangWatchはLLMパイプラインを制御する力を与えてくれます。私たちのテスト質問である「今日のフランス語は何ですか?」は、AIの応答を追跡し改善することがいかに簡単であるかを示しました。
AIゲームを次のレベルに引き上げる準備はできていますか?app.langwatch.aiにアクセスし、サインアップして、今日からLangWatchを試してみてください。
最大限の生産性で開発チームが協力できる統合されたオールインワンプラットフォームが欲しいですか?
Apidogはあなたのすべての要求に応え、Postmanをはるかに手頃な価格で置き換えます!